Edward Huang
On Dec 20, 2019, we released TiDB 3.1 Beta. In this version, TiDB introduced two significant features, Follower Read and Backup & Restore (BR), and enriched optimizer hints.
For TiDB 3.1 Beta, Follower Read is a highlight open-source feature. To understand how important this feature is, you’ll need a bit of background. TiDB’s storage engine, TiKV, stores data in basic units called Regions. Multiple replicas of a Region form a Raft group. When a read hotspot appears in a Region, the Region leader can become a read bottleneck for the entire system. In this situation, enabling the Follower Read feature can significantly reduce the load on the leader and improve the read throughput of the whole system by balancing the load among multiple followers.
We wrote only 26 lines of code to implement Follower Read. In our benchmark test, when this feature was enabled, we could roughly double the read throughput of the entire system.
In this post, I’ll guide you through why we introduced Follower Read, how we implement it, and our future plans for it.
Note that this post assumes that you have some basic knowledge of the Raft consensus algorithm and TiDB’s architecture.
What is Follower Read
The Follower Read feature lets any follower replica in a Region serve a read request under the premise of strongly consistent reads.
This feature improves the throughput of the TiDB cluster and reduces the load on the Raft leader. It contains a series of load balancing mechanisms that offload TiKV read loads from the leader replica to the follower replicas in a Region.
TiKV’s Follower Read implementation guarantees the linearizability of single-row data reading. Combined with snapshot isolation in TiDB, this implementation also provides users with strongly consistent reads.
Why we introduced Follower Read
In the TiKV architecture, we use the Raft algorithm to ensure data consistency. But in the previous mechanism, only the leader in a Region handled heavy workloads, and the calculation resources of followers were not put to use. Therefore, we introduced Follower Read to handle read requests on followers to reduce the load on the leader.
The TiKV architecture
TiKV uses the Raft algorithm to guarantee data consistency. The goal of TiKV is to support 100+ TB of data, but it is impossible for one Raft group to do that. Therefore, we need to use multiple Raft groups, which is Multi-Raft. See our previous post The Design and Implementation of Multi-Raft.
Implementing Raft in the TiKV architecture
TiKV divides data into Regions. By default, each Region has three replicas and these Region replicas form a Raft group. As data writes increase, if the size of the Region or the number of keys reaches a threshold, a Region Split occurs. Conversely, if data is deleted and the size of a Region or the amount of keys shrinks, we can use Region Merge to merge smaller adjacent Regions. This relieves some stress on Raftstore.
The problem with the TiKV architecture
The Raft algorithm achieves consensus via an elected leader. A server in a Raft group is either a leader or a follower, and, if a leader is unavailable, it can be a candidate in an election. The leader replicates logs to the followers.
Although TiKV can spread Regions evenly on each node, only the leader can provide external services. The other two followers only receive the data replicated from the leader, or vote to elect a Raft leader when doing a failover. Simply put, at the Region level, only the leader deals with heavy workloads, while followers are maintained as cold standbys.
Sometimes when there is some hot data, the resources of the Region leader’s machine are fully occupied. Although we can forcibly split the Region and then move the data to another machine, this operation always lags, and the calculation resources of followers are not used.
Here comes a question: can we handle the client’s read request on followers? If yes, we can relieve the load on the leader.
The solution is Follower Read.
How we implement Follower Read
The implementation of Follower Read is based on the ReadIndex algorithm. Before elaborating on Follower Read, let me introduce ReadIndex first.
The ReadIndex algorithm
This section discusses how the ReadIndex algorithm solves the linearizability issue.
The linearizability issue for the Raft algorithm
How do we ensure that we can read the latest data on followers? Can we just return the data about the latest committed index on followers to the client?
The answer is no, because Raft is a quorum-based algorithm. To commit a log, you don’t need to successfully write data to all the replicas of a Region (also known as peers). Instead, when a log is committed to the majority of peers, it means that it is successfully written to TiKV. In this case, the local data on a follower might be stale. This violates linearizability.
In fact, in trivial Raft implementation, even if the leader handles all loads, the stale data problem may still occur. For example, when a network partition occurs, the old leader is isolated in the minority of nodes. At the same time, the majority of nodes have elected a new leader. But the old leader doesn’t know that, and it may return stale data to the client during its leader lease.
ReadIndex as the solution to the linearizability issue
The quorum reads mechanism helps solve this problem, but it might consume a lot of resources or take too long. Can we improve its effectiveness? The crucial issue is that the old leader is not sure whether it is the latest leader. Therefore, we need a method for the leader to confirm its leader state. This method is called the ReadIndex algorithm. It works as follows:
- When the current leader processes a read request, the system records the current leader’s latest committed index.
- The current leader ensures that it’s still the leader by sending a heartbeat to the quorum.
- After the leader confirms its leader state, it returns this entry.
This way, linearizability is not violated. Although the ReadIndex algorithm needs network communication for the majority of the cluster, this communication just transmits metadata. It can remarkably reduce network I/O, and thus increase the throughput. Furthermore, TiKV goes beyond the standard ReadIndex algorithm and implements LeaseRead, which guarantees that the leader lease is shorter than the election timeout of re-electing a new leader.
Implementation and issues of Follower Read
This section shows how we implement Follower Read and some of this feature’s issues.
The current implementation of Follower Read
How do we ensure that we can read the latest data on followers? Maybe you’ll consider this common policy: the request is forwarded to the leader, and then the leader returns the latest committed data. The follower is used as a proxy. The idea is simple and safe to implement.
You can also optimize this policy. The leader only needs to tell followers the latest committed index, because in any case, even if a follower hasn’t stored this log locally, the log is applied locally sooner or later.
Based on this thought, TiDB currently implements the Follower Read feature this way:
1. When the client sends a read request to a follower, the follower requests the leader’s committed index.
2. After the follower gets the leader’s latest committed index and applies the index to itself, the follower returns this entry to the client.
Issues for Follower Read
Currently, the Follower Read feature has two issues:
Issue #1: linearizability
TiKV uses an asynchronous Apply, which might violate linearizability. Although the leader tells followers the latest committed index, the leader applies this log asynchronously. A follower may apply this s log before the leader does. As a result, we can read this entry on the follower, but it may take a while to read it on the leader.
Although we can’t ensure linearizability for the Raft layer, Follower Read can guarantee snapshot isolation for the database distributed transaction layer. If you’re familiar with the Percolator algorithm, you can get that:
- When we execute a point get query, we use
UINT64_MAXas the timestamp to read data. Because only one row of data in only one Region is accessed, we can guarantee snapshot isolation for a transaction. - If the data for the committed timestamp (ts) can be read on the follower, but other SQL statements within the same transaction temporarily can’t read this ts on the leader, a lock inevitably occurs. The subsequent processing of the lock can guarantee snapshot isolation.
The two facts above ensure that when Follower Read is enabled, TiDB’s transaction still implements snapshot isolation. Thus, transaction correctness isn’t affected.
Issue #2: read latency
Our current Follower Read implementation still uses a remote procedure call (RPC) to ask the leader for the committed index. Therefore, even though we use Follower Read, read latency remains high.
For this issue, even though this solution doesn’t significantly improve latency, it helps improve read throughput and reduce the load on the leader.
Therefore, the Follower Read feature is a fine optimization.
Benchmarks for Follower Read
We ran tests in four scenarios and arrived at the following conclusions:
- In the multi-region architecture, when Follower Read was enabled, the client could read data from the local data center. This reduced the network bandwidth usage. When the data volume reached a certain scale, Follower Read remarkably improved the system performance. (See Scenario #1 and Scenario #2 below.)
- Follower Read can effectively increase the read throughput of the entire system and balance the hotspot read pressure. (See Scenario #3 and Scenario #4 below.)
You can read this section to get more details.
Test environment
We used the following machines for testing::
- UCloud 16C 32 GB 100 GB SSD in Beijing, China
- UCloud 16C 32 GB 100 GB SSD in Shanghai, China
We tested the bandwidth and latency, and determined the following:
- Bandwidth was 297 Mbits/sec.
- Latency ranged from 27.7 to 28.3 ms.
We used Yahoo! Cloud Serving Benchmark (YCSB) to import 10,000,000 rows of data and tested the scan performance for different rows.
We performed raw key-value (KV) scan tests. By adjusting the number of scan keys, we got requests of different data sizes for testing.
Test results
Scenario #1
Scenario description: The follower and the client were in the same data center (DC). The leader was in a data center in another region. The leader served read requests.
Test results:
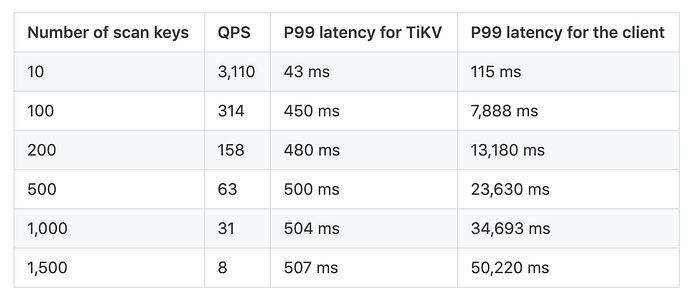
Result analysis:
When the latency between the client and TiKV increased, due to the sliding window mechanism, the corresponding TCP connection bandwidth decreased. When the data volume was large, we even observed a lot of DeadlineExceededlogs.
The reason behind the high P99 latency for TiKV is because the leader lease expired. One-third of the read requests should read ReadIndexbefore they are executed.
Scenario #2
Scenario description: The follower and the client were in the same data center. The leader was in a data center in another region. The follower served read requests.
Test results:

Result analysis:
Follower Read reduced cross-DC traffic. Thus, it avoided the impact of the TCP sliding window mechanism on a high-latency network. When the amount of data in a request was small, the impact on the cross-DC latency was big. When the amount of data in a request was big, the impact on the cross-DC latency was small. In this case, when Follower Read was enabled, read throughput did not change very much.
Scenario #3
Scenario description: The leader and the client were on the same node. The leader served read requests.
Test results:

Result analysis:
The client had higher latency than TiKV. We ran netstat and found that there were many packets in the TCP Send-Q. This means that the TCP sliding window mechanism limited the bandwidth.
Scenario #4
Scenario description: The leader, client, and follower were in the same data center. The follower served read requests.
Test results:

Result analysis:
When the amount of data in the read request was small and the request processing time was short, the impact of Follower Read on the latency was big. This was because the Follower Read feature included an internal remote procedure call (RPC). The RPC operation took up a large portion of the read request processing time. Therefore, it had a big influence on read throughput.
What’s next for Follower Read
This feature seems simple, but it’s really important. In the future, we’ll use it in even more ways to improve TiDB’s performance.
Strategies for varied-heat data
You might ask me a question: if I run a large query on a table, will it affect the ongoing online transaction processing (OLTP) transaction?Although we have an I/O priority queue built in TiKV, which prioritizes important OLTP requests, it still consumes the resources of the machine with the leader state.
A corner case is a small hot table with many more read operations than write operations. Although hot data is cached in memory, when the data is extremely hot, a CPU or network I/O bottleneck occurs.
Our previous post TiDB Internal (III) — Scheduling mentions that we use a separate component called Placement Driver (PD) to schedule and load-balance Regions in the TiKV cluster. Currently, the scheduling work is limited to splitting, merging, and moving Regions, and transferring the leader. But in the near future, TiDB will be able to dynamically use different replica strategies for data of different heat degrees.
For example, if we find a small table extremely hot, PD can quickly let TiKV dynamically create multiple (more than three) read-only replicas of this data, and use the Follower Read feature to divert the load from the leader. When the load pressure is mitigated, the read-only replicas are destroyed. Because each Region in TiKV is small (96 MB by default), TiDB can be very flexible and lightweight when doing this.
Local Read based on Follower Read
Currently, even though TiDB is deployed across data centers and distributes data replicas among these data centers, it is the leader that provides services for each piece of data. This means that applications need to be as close to the leader as possible. Therefore, we usually recommend that users deploy applications in a single data center, and then make PD focus leaders on this data center to process read and write requests faster. Raft is only used to achieve high availability across data centers.
For some read requests, if we can process these requests on a nearby node, we can reduce the read latency and improve read throughput.
As mentioned above, the current implementation of Follower Read does little to reduce read latency. Can we get the local committed log without asking the leader? Yes, in some cases.
As we discussed in our previous post MVCC in TiKV, TiDB uses multi-version concurrency control (MVCC) to control transaction concurrency. Each entry has a unique, monotonically increasing version number.
Next, we’ll combine Follower Read with MVCC. If the version number of the data in the latest committed log on the local node is greater than that of the transaction initiated by the client, the system returns the data in the latest committed log on the local node. This won’t violate the atomicity, consistency, isolation, durability (ACID) properties of transactions.
In addition, for some scenarios where data consistency is not a strict requirement, it makes sense to directly support reads of low isolation level in the future. When TiDB supports reads of low isolation level, its performance might improve dramatically.
Conclusion
The Follower Read feature uses a series of load balancing mechanisms to offload read requests on the Raft leader onto its followers in a Region. It ensures the linearizability of single-row data reads and offers strongly consistent reads when combined with TiDB’s snapshot isolation.
Follower Read helps reduce the load on the Region leader and substantially enhances the throughput of the entire system. If you’d like to try it out, see our user document.
We’ve just taken the first step to craft Follower Read, and we’ll make continuous efforts to optimize this feature in the future. If you’re interested in it, you’re welcome to test it or contribute to our project.
Originally published at www.pingcap.com on Feb 5, 2020
